JavaWeb学习中关于SpringBootJPA的相关知识 💯💤
Spring Data JPA
¶ORM
¶1. ORM
ORM(Object-Relational Mapping)对象关系映射,建立实体类与数据库表之间的联系,从而实现操作实体类对象就等于操作数据库表的目的。
应用场景分析:
| 实体类 | 数据库表 |
|---|---|
| User | t_user |
| Integer userId | id |
| String userName | name |
| String userAddress | address |
在实现一个应用程序时,往往会设计很多关于数据库持久层的代码,从数据库进行增删改查,这些代码大多重复繁琐,ORM可以大大减少重复代码。
比如,通过obj.save(user)的操作实现存储用户的功能。在拼接Sql时,String sql = insert into ____values____,这是通用的Sql模板,当实体类与数据库表建立联系时,user中存在三个属性,save方法获得实体类名user和其中的属性,同时由ORM框架映射得到与之相关联的数据库表,从而在方法中实现Sql的自动拼接。
¶2. Hibernate
Hibernate是一个开源的ORM框架,它对JDBC进行了对象封装,它将POJO与数据库表建立映射关系,是一个全自动的ORM框架,可以自动生成SQL语句,自动执行。
¶3. JPA
- JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。JPA通过注解描述对象和表的映射关系,并将运行期的实体对象持久化到数据库中。
- JPA规范本质上是一种ORM规范,而不是ORM框架,因为JPA并未提供ORM实现,它只是制订了一些规范,提供了一些编程的API接口,具体实现则由服务厂商来提供实现。
- JPA和Hibernate的关系就像JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。也就是说,如果使用JPA规范进行数据库操作,底层需要Hibernate作为其实现类完成数据持久化工作。
¶JPA入门–保存用户信息
¶1. pom.xml中导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.hibernate.version>5.0.7.Final</project.hibernate.version>
</properties>
<dependencies>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- c3p0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- log日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
</project>
¶2. 在实体类中使用注解建立与数据库表的映射
@Entity
@Table(name = "cst_customer")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId; //客户的主键
@Column(name = "cust_name")
private String custName;//客户名称
@Column(name="cust_source")
private String custSource;//客户来源
@Column(name="cust_level")
private String custLevel;//客户级别
@Column(name="cust_industry")
private String custIndustry;//客户所属行业
@Column(name="cust_phone")
private String custPhone;//客户的联系方式
@Column(name="cust_address")
private String custAddress;//客户地址
...
}
- 实体类与表的映射关系
- @Entity:声明实体类。
- @Table:配置实体类和表的映射关系,name属性 : 配置数据库表的名称。
- 实体类中属性和表中字段的映射关系
- @Id:声明主键
- @GeneratedValue:配置主键的生成策略。
- strategy=GenerationType.IDENTITY :自增,底层数据库要支持自增长的方式,如mysql。
- strategy=GenerationType.SEQUENCE : 序列,底层数据库必须支持序列,如oracle。
- 其余两种不常用。
- @Column:配置属性和字段的映射关系,name属性:数据库表中字段的名称。
¶3. 配置JPA的核心配置文件
在java工程的src路径下创建一个名为META-INF的文件夹,在此文件夹下创建一个名为persistence.xml的配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0">
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<!--jpa的实现方式 -->
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<!--配置jpa实现方的配置信息-->
<properties>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="111111"/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql:///jpa"/>
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="update" />
</properties>
</persistence-unit>
</persistence>
- persistence-unit配置持久化单元。
- name:持久化单元名称
- transaction-type:事务管理的方式
- JTA:分布式事务管理
- RESOURCE_LOCAL:本地事务管理
- provider标签用于配置JPA的实现方式,使用的Hibernate的底层实现。
- properties标签配置数据库和Hibernate相关信息。
- hibernate.show_sql:显示sql,取值为true时在程序执行时,控制台将会输出Hibernate拼接的Sql。
- hibernate.hbm2ddl.auto:自动创建数据库表
- create:程序运行时创建数据库表(如果有表,先删除表再创建)。
- update:程序运行时创建表(如果有表,不会创建表)。
- none:不会创建表。
¶4. 测试JPA
public class JpaTest {
@Test
public void testSave() {
//1.加载配置文件创建工厂(实体管理器工厂)对象
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
//2.通过实体管理器工厂获取实体管理器
EntityManager em = factory.createEntityManager();
//3.获取事务对象,开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//4.完成增删改查操作:保存一个客户到数据库中
Customer customer = new Customer();
customer.setCustName("张三");
customer.setCustIndustry("教育");
//保存
em.persist(customer);
//5.提交事务
tx.commit();
//6.释放资源,先创建的后关闭,后创建的先关闭
em.close();
factory.close();
}
}
JPA操作的操作步骤
-
调用
Persisitence类的静态方法createEntityMnagerFactory,加载配置文件并创建实体管理器工厂EntityManagerFactory,其中参数名为配置文件中配置的持久化单元名称。-
在创建
EntityManagerFactory的过程中,内部维护了数据库信息、缓存信息、实体管理器对象并根据配置创建数据库表。因此,该对象比较浪费资源。 -
EntityManagerFactory对象是一个线程安全的对象,为了解决其资源开销大的问题,可以使用静态代码块创建一个公用的EntityManagerFactory对象。public class JpaUtils { private static EntityManagerFactory factory; static { factory = Persistence.createEntityManagerFactory("myJpa"); } public static EntityManager getEntityManager() { return factory.createEntityManager(); } }- 通过静态代码块的形式,当程序第一次访问此工具类时,创建一个公共的实体管理器工厂对象。
- 第一次访问getEntityManager方法:经过静态代码块创建一个factory对象,再调用方法创建一个EntityManager对象。
- 第二次方法getEntityManager方法:直接通过一个已经创建好的factory对象,创建EntityManager对象。
-
-
根据实体管理器工厂
EntityManagerFactory,调用其方法createEntityManager创建实体管理器EntityManager。 -
EntityManager对象创建事务并开启事务。EntityManager是完成持久化操作的核心对象,实体类作为普通 java对象,只有在调用EntityManager将其持久化后才会变成持久化对象。- 主要方法:
- persist:保存
- merge : 更新操作
- remove : 删除操作
- find/getReference : 根据id查询
-
增删改查操作
-
提交事务
-
释放资源
¶JPA增删改查
EntityManager是完成持久化操作的核心对象,JPA增删改查的操作都是通过该对象的相关方法实现的。
¶1. 根据id查询
-
方法:find(class,id),getReference(class,id)。
-
参数:class表示查询结果封装对象对应的字节码,id表示查询的id值。
-
find方法为立即加载,当调用该方法时就去查询数据库,getReference方法为延迟加载,得到的查询对象是一个动态代理对象,只有当调用查询对象结果时才会去数据库中执行查询。
@Test public void testFind() { //1.通过工具类获取entityManager EntityManager entityManager = JpaUtils.getEntityManager(); //2.开启事务 EntityTransaction tx = entityManager.getTransaction(); tx.begin(); //3.增删改查 -- 根据id查询客户 Customer customer = entityManager.find(Customer.class, 1l); //4.提交事务 tx.commit(); //5.释放资源 entityManager.close(); }
¶2. 删除操作
-
方法:find(class,id),remove(obj)。
-
参数:obj表示通过find查询到对象。
-
删除操作首先需要去数据库中查询,然后调用remove方法删除查询到的该对象。
@Test public void testRemove() { ... //3.增删改查 -- 删除客户 //i 根据id查询客户 Customer customer = entityManager.find(Customer.class,1l); //ii 调用remove方法完成删除操作 entityManager.remove(customer); ... }
¶3. 修改更新操作
-
方法:find(class,id),merge(obj)。
-
参数:obj表示通过find查询到对象。
-
更新操作首先需要去数据库中查询,然后对查询对象的属性进行修改,最后调用merge方法更新修改内容。
@Test public void testUpdate() { ... //3.增删改查 -- 更新操作 //i 查询客户 Customer customer = entityManager.find(Customer.class,1l); //ii 更新客户 customer.setCustIndustry("it"); entityManager.merge(customer); ... }
¶4. JPQL进行复杂查询
-
JPQL全称Java Persistence Query Language,其特征与SQL语句类似,JPQL完全面向对象,通过类名和属性访问,而不是表名和表的属性。
-
查询流程与基本增删改查操作类似,其中在上述第三步进行查询时,包括以下步骤:
- 创建query查询对象
- 对参数进行赋值
- 查询,并得到返回结果
-
查询全部
- sql:SELECT * FROM cst_customer
- jqpl:from cn.itcast.domain.Customer
-
倒序查询
- sql:SELECT * FROM cst_customer ORDER BY cust_id DESC
- jpql:from Customer order by custId desc
-
统计次数
- sql:SELECT COUNT(cust_id) FROM cst_customer
- jpql:select count(custId) from Customer
-
条件查询
- sql:SELECT * FROM cst_customer WHERE cust_name LIKE ?
- jpql : from Customer where custName like ?
-
案例:条件查询
@Test public void testCondition() { ... //3.查询全部 //i.根据jpql语句创建Query查询对象 String jpql = "from Customer where custName like ? "; Query query = em.createQuery(jpql); //ii.对参数赋值 -- 占位符参数 //第一个参数:占位符的索引位置(从1开始),第二个参数:取值 query.setParameter(1,"zhang"); //iii.发送查询,并封装结果 List list = query.getResultList(); for(Object obj : list) { System.out.println(obj); } ... }
¶Spring Data JPA入门
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。使用该框架只需要编写dao层的接口,就可以实现CRUD以及复杂查询的操作,它提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案。
¶1. 导入坐标
pom.xml
SpringDataJPA基于Spring框架实现,主要的依赖坐标包括:Spring、Hibernate、JPA相关、数据库相关以及日志相关。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.sucrelt</groupId>
<artifactId>SpringBoot-01-SpringDataJPA</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spring.version>4.2.4.RELEASE</spring.version>
<hibernate.version>5.0.7.Final</hibernate.version>
<slf4j.version>1.6.6</slf4j.version>
<log4j.version>1.2.12</log4j.version>
<c3p0.version>0.9.1.2</c3p0.version>
<mysql.version>5.1.6</mysql.version>
</properties>
<dependencies>
<!-- junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
<!-- spring begin -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.6.8</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring对orm框架的支持包-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring end -->
<!-- hibernate begin -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.2.1.Final</version>
</dependency>
<!-- hibernate end -->
<!-- c3p0 begin -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>${c3p0.version}</version>
</dependency>
<!-- c3p0 end -->
<!-- log begin -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- log end -->
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- spring data jpa 的坐标 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.9.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- el begin 使用spring data jpa 必须引入 -->
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.4</version>
</dependency>
<!-- el end -->
</dependencies>
</project>
¶2. 编写配置文件
Spring的配置文件applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<!--spring 和 spring data jpa的配置-->
<!-- 1.创建entityManagerFactory对象交给spring容器管理-->
<bean id="entityManagerFactoty" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource"/>
<!--配置的扫描的包(实体类所在的包) -->
<property name="packagesToScan" value="cn.sucrelt.domain"/>
<!-- jpa的实现厂家 -->
<property name="persistenceProvider">
<bean class="org.hibernate.jpa.HibernatePersistenceProvider"/>
</property>
<!--jpa的供应商适配器 -->
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<!--配置是否自动创建数据库表 -->
<property name="generateDdl" value="false"/>
<!--指定数据库类型 -->
<property name="database" value="MYSQL"/>
<!--数据库方言:支持的特有语法 -->
<property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect"/>
<!--是否显示sql -->
<property name="showSql" value="true"/>
</bean>
</property>
<!--jpa的方言 :高级的特性 -->
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"/>
</property>
</bean>
<!--2.创建数据库连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="root"></property>
<property name="password" value="123456"></property>
<property name="jdbcUrl" value="jdbc:mysql:///jpa"></property>
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
</bean>
<!--3.整合spring dataJpa-->
<jpa:repositories base-package="cn.sucrelt.dao" transaction-manager-ref="transactionManager"
entity-manager-factory-ref="entityManagerFactoty"></jpa:repositories>
<!--4.配置事务管理器 -->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactoty"></property>
</bean>
<!-- 4. 声明式事务txAdvice-->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="save*" propagation="REQUIRED"/>
<tx:method name="insert*" propagation="REQUIRED"/>
<tx:method name="update*" propagation="REQUIRED"/>
<tx:method name="delete*" propagation="REQUIRED"/>
<tx:method name="get*" read-only="true"/>
<tx:method name="find*" read-only="true"/>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 5.aop-->
<aop:config>
<aop:pointcut id="pointcut" expression="execution(* cn.sucrelt.service.*.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut"/>
</aop:config>
<!-- 6. 配置包扫描-->
<context:component-scan base-package="cn.sucrelt"></context:component-scan>
</beans>
- 使用
entityManagerFactory标签将实体管理器交给Spring管理,其中最主要的是配置实体类扫描的包以及配置JPA底层实现的厂商。 - 使用
jpa:repositories标签将JPA整合到Spring中,其中base-package属性为dao类所在的包。 - 使用
context:component-scan标签配置Spring的注解扫描。 - 其余的配置与Spring中类似,或仅限了解即可。
¶3. 编写实体类并使用注解配置映射关系
此部分与JPA中的实体类一样,不再赘述。
¶4. 编写dao接口
- Spring Data JPA是spring提供的一款对于数据访问层(Dao层)的框架,使用Spring Data JPA,只需要按照框架的规范提供dao接口,不需要实现类就可以完成数据库的增删改查、分页查询等方法的定义,极大的简化了我们的开发过程。
- 在Spring Data JPA中,对于定义符合规范的Dao层接口,需要遵循:
- 创建一个Dao层接口,并继承
JpaRepository和JpaSpecificationExecutor类。 - 提供相应的泛型。
JpaRepository中的两个泛型分别表示:实体类类型以及主键类型。JpaSpecificationExecutor中的泛型表示实体类类型。
JpaRepository用于实现基本的CRUD操作,JpaSpecificationExecutor用于实现分页等复杂查询。
- 创建一个Dao层接口,并继承
¶5. 测试CRUD操作
测试文件与Spring中测试文件类似。
自动注入并调用dao接口,由于定义的该接口继承了上述的两个类,其中包括常见的数据库操作方法,直接通过类对象调用即可。
dao中的方法与JPA的方法类似:
- save方法可以实现保存和更新:根据传递的对象是否存在主键id进行判断,如果没有id主键属性执行保存操作,如果存在主键则根据id查询数据,并更新数据,更新数据时会更新表中所有字段,未提供更新值的字段会被置空。
@RunWith(SpringJUnit4ClassRunner.class) //声明spring提供的单元测试环境
@ContextConfiguration(locations = "classpath:applicationContext.xml")//指定spring容器的配置信息
public class CustomerDaoTest {
@Autowired
private CustomerDao customerDao;
@Test
public void testFindOne() {
Customer customer = customerDao.findOne(4l);
System.out.println(customer);
}
@Test
public void testSave() {
Customer customer = new Customer();
customer.setCustName("zhangsan");
customer.setCustIndustry("it");
customerDao.save(customer);
}
@Test
public void testUpdate() {
Customer customer = new Customer();
customer.setCustId(4l);
customer.setCustName("lisi");
customerDao.save(customer);
}
@Test
public void testDelete() {
customerDao.delete(3l);
}
@Test
public void testFindAll() {
List<Customer> list = customerDao.findAll();
for (Customer customer : list) {
System.out.println(customer);
}
}
}
¶⭐️Spring Data JPA调用过程分析
¶1. 图示
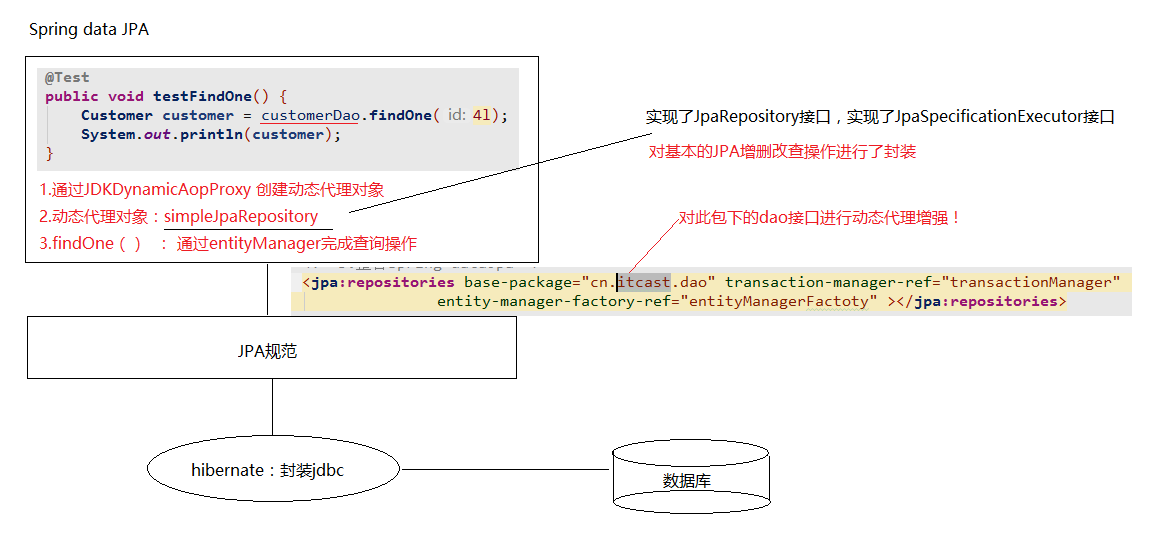
¶2. 分析
- 通过debug方法可以查看到,当调用实体类的dao对象时,实际上是通过
JdkDynamicAopProxy类中的invoke方法创建了一个动态代理对象。 - 在invoke方法中,生成的动态代理对象target为
SimpleJpaRepository类的对象。 - 查看
SimpleJpaRepository类,其与实现的dao接口一样,继承了JpaRepository和JpaSpecificationExecutor并实现了其中的方法,如findOne。 - 以findOne方法为例,
SimpleJpaRepository中的该方法内部通过em.find()实现具体操作,而em正是JPA的核心对象EntityManager。也就是说,SimpleJpaRepository类中封装了JPA的操作,借助JPA的api完成数据库的CRUD。 - 最后,JPA底层通过Hibernate完成数据库操作。
- 因此,Spring Data JPA只是对标准JPA操作进行了进一步封装,简化了Dao层代码的开发。
¶Spring Data JPA查询方式
¶1. 接口自带方法
除了基本的CRUD操作外,dao接口中还包含其他一些方法。
- count方法:查询总的记录条数;
- exists方法:参数为id值,查询指定id值的用户是否存在,具体执行的sql方式为查找id为4的对象个数,判断个数是否为0;
- getOne方法:根据指定id获取对象.
- findOne方法底层实现使用em.find(),为立即加载;
- getOne方法底层实现使用em.getReference(),为延迟加载,在调用该方法时,需要在响应的执行方法上加上
@Transactional注解,表示与事务相关。
¶2. JPQL方式
在Spring Data JPA中使用JPQL方式进行查询,可以自定义一些查询方法,将JPQL语句配置到接口方法上。
-
特有的查询:需要在dao接口上配置方法;
-
在新添加的方法上,使用
@Query注解的形式配置jpql查询语句。 -
例:根据用户名和ID进行查询
-
接口文件
public interface CustomerDao extends JpaRepository<Customer, Long>, JpaSpecificationExecutor<Customer> { @Query(value = "from Customer where custName = ?2 and custId = ?1") public Customer findCustNameAndId(Long id, String name); } -
测试文件
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class JpqlTest { @Autowired private CustomerDao customerDao; @Test public void testFindCustNameAndId() { Customer customer = customerDao.findCustNameAndId(1l,"王二"); System.out.println(customer); } } -
⭐️注意
关于多参数占位符的问题,在默认情况下JPQL语句中的占位符与方法中参数列表的顺序相一致,可以通过**?+索引**的方式在JPQL语句中指定占位符对应的取值参数。
-
-
例:使用JPQL实现更新用户的操作
-
接口文件
public interface CustomerDao extends JpaRepository<Customer, Long>, JpaSpecificationExecutor<Customer> { @Query(value = " update Customer set custName = ?2 where custId = ?1 ") @Modifying public void updateCustomer(long custId, String custName); } -
测试文件
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class JpqlTest { @Autowired private CustomerDao customerDao; @Test @Transactional //添加事务的支持 @Rollback(value = false) public void testUpdateCustomer() { customerDao.updateCustomer(4l,"麻子"); } } -
⭐️注意
- 在接口文件中对方法需要额外使用
@Modifying注解声明该方法执行的是更新操作; - 在测试过程中必须添加事务支持,同时,SpringDataJpa中的事务默认会进行回滚,因此需要设置
@Rollback(value = false)取消回滚。
- 在接口文件中对方法需要额外使用
-
¶3. SQL方式
在SpringDataJPA中,同样可以使用SQL语句进行查询,使用方式与上述使用JPQL的方式类似,其中,需要在@Query注解中使用nativeQuery属性取值为true,表示采用本地查询,即SQL查询。
@Query(value="select * from cst_customer where cust_name like ?1",nativeQuery = true)
public List<Object [] > findSql(String name);
¶4. 方法命名查询
-
使用方法命名进行查询是对jpql查询的更加深入一层的封装,只需要按照SpringDataJPA提供的方法名称规则定义方法,不需要再配置jpql语句,就可以完成查询。
-
例如:findBy表示查询方法,其后跟一个首字母大写的属性名表示查询条件,如CustName,该方法名为findByCustName,不需要JPQL语句就可以直接调用实现根据用户名查询。
¶Spring Data JPA动态查询
¶1. 原理分析
-
在实际查询过程中,根据前端传入的参数得到相应的条件进行查询,比如,查询一个用户的方法findOne,条件可以是根据用户名,也可以是根据行业。因此,可以编写一个通用的动态查询方法,在执行查询时根据具体存在的条件动态生成JPQL语句进行查询。
-
动态查询使用的dao接口中继承的
JpaSpecificationExecutor类中的方法,该类中的方法均包含一个Specification参数,表示的是动态查询的条件。 -
执行查询前需要生成一个
Specification类的对象作为参数,该类包含一个toPredicate方法,用于构造查询条件。 -
Predicate toPredicate(Root<T> var1, CriteriaQuery<?> var2, CriteriaBuilder var3);-
其中root用于设置查询条件中的对象属性,CriteriaBuilder用于设置查询的比较方式,CriteriaQuery不常用。
-
例如:
select * from cst_customer where cust_name = '张三'查询条件为
cust_name = '张三',root参数用于设置的为cust_name,对应对象属性为custName,CB参数用于设置='张三'。 -
在CB中包含很多查询匹配方法,如equal、like、gt、lt、and、or等,对应模糊匹配和精确匹配的方式。
-
¶2. 单条件查询
-
代码
@Test public void testSpec() { //匿名内部类 Specification<Customer> spec = new Specification<Customer>() { public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) { //构造查询条件 //1.获取比较的属性 Path<Object> custName = root.get("custName"); //2.设置匹配方式 Predicate predicate = cb.equal(custName, "张三"); return predicate; } }; Customer customer = customerDao.findOne(spec); System.out.println(customer); } -
在执行查询时,首先创建Specification对象,同时通过匿名内部类的方式设置其中的toPredicate方法,root和cb对象设置的条件相当于JPQL语句中的
custName="张三",最后调用查询方法并传入参数进行查询。
¶3. 多条件查询
-
代码
@Test public void testSpec1() { Specification<Customer> spec = new Specification<Customer>() { public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) { //1.构造查询条件 //客户名,模糊查询 Path<Object> custName = root.get("custName"); Predicate p1 = cb.like(custName.as(String.class), "张"); Path<Object> custIndustry = root.get("custIndustry"); Predicate p2 = cb.equal(custIndustry, "it"); //2.联合查询条件 Predicate predicates = cb.and(p1, p2); return predicates; } }; List<Customer> customers = customerDao.findAll(spec); for (Customer customer : customers) { System.out.println(customer); } } -
多条件查询时与单个条件查询过程类似,分别设置每个查血条件,最后通过CB中的and或者or方法将多个条件联合起来。
-
对于模糊查询like以及gt,lt,ge,le等查询方式,CB对象在调用对应方法时,其中的参数不能直接使用对象属性进行比较,需要使用
path.as(比较类型的字节码对象)作为参数。
¶4. 排序和分页
-
排序
-
在调用findAll方法时,可以选择带有Sort参数的findAll方法,表示查询的结果会进行排序。
-
Sort对象用于表示排序,使用前需要实例化该对象,需要调用其构造方法
public Sort(Sort.Direction direction, String... properties)并传入参数。- 第一个参数表示排序的顺序:Sort.Direction.DESC表示倒序,Sort.Direction.ASC表示升序。
- 第二个参数表示进行排序的属性名。
-
代码
@Test public void testSpec1() { Specification<Customer> spec = new Specification<Customer>() {...}; //创建排序对象,需要调用构造方法实例化sort对象 Sort sort = new Sort(Sort.Direction.DESC, "custId"); List<Customer> customers = customerDao.findAll(spec, sort); for (Customer customer : customers) { System.out.println(customer); } }
-
-
分页
-
在调用findAll方法时,可以选择带有Pageable参数的findAll方法,表示查询的结果会进行分页。
-
Pageable对象时SpringDataJPA中的封装好的pageBean对象,使用前需要调用其实现类
PageRequest实例化 -
PageRequest(page,size)- 第一个参数page表示查询的页数,从0开始。
- 第二个参数size表示每页的数量。
-
调用带有分页查询的查询方法findAll,最终的返回值为一个Page类型的对象。该对象包含以下方法:
- getContent():获取数据列表集合。
- getTotalElements():获取总条数。
- getTotalPages():得到总页数。
-
代码
@Test public void testSpec1() { Specification<Customer> spec = new Specification<Customer>() {...}; Pageable pageable = new PageRequest(0, 2); Page<Customer> page = customerDao.findAll(spec, pageable); System.out.println(page.getContent()); //得到数据集合列表 System.out.println(page.getTotalElements());//得到总条数 System.out.println(page.getTotalPages());//得到总页数 }
-
¶Spring Data JPA多表操作
¶1. 多表关系分析
- 在数据库的多表关系中,主要为一对多和多对多关系。
- 一对多:一的一方作为主表,多的一方作为从表,在从表中设置一列外键属性,简历主从表的联系,取值为主表中的主键值。
- 多对多:使用中间表描述主从表的联系,中间表至少包括两个字段,作为外键,取值分别为主从表的主键值,这二者又构成了联合主键。
- 在ORM框架中,需要将实体类和数据库表映射起来。在实体类中,类之间可以存在包含关系,因此可以用这种包含关系描述主从表的关系。
¶2. 一对多
-
案例:公司(Customer)和员工(Linkman)
-
编写实体类
-
包含关系描述主从表关系:公司实体类中包含一个员工类的集合,员工实体类中包含一个公司类的对象
-
主表实体类
@Entity @Table(name="cst_customer") public class Customer implements Serializable { @Id @GeneratedValue(strategy=GenerationType.IDENTITY) @Column(name="cust_id") private Long custId; @Column(name="cust_name") private String custName; @Column(name="cust_source") private String custSource; @Column(name="cust_industry") private String custIndustry; @Column(name="cust_level") private String custLevel; @Column(name="cust_address") private String custAddress; @Column(name="cust_phone") private String custPhone; //一对多关系映射 @OneToMany(targetEntity=LinkMan.class) @JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id") private Set<LinkMan> linkmans = new HashSet<LinkMan>(0); ...//省略Setter、Getter、toString方法 } -
从表实体类
@Entity @Table(name="cst_linkman") public class LinkMan implements Serializable { @Id @GeneratedValue(strategy=GenerationType.IDENTITY) @Column(name="lkm_id") private Long lkmId; @Column(name="lkm_name") private String lkmName; @Column(name="lkm_gender") private String lkmGender; @Column(name="lkm_phone") private String lkmPhone; @Column(name="lkm_mobile") private String lkmMobile; @Column(name="lkm_email") private String lkmEmail; @Column(name="lkm_position") private String lkmPosition; @Column(name="lkm_memo") private String lkmMemo; //多对一关系映射 @ManyToOne(targetEntity=Customer.class) @JoinColumn(name="lkm_cust_id",referencedColumnName="cust_id") private Customer customer; ... } -
在主表和从表对应的实体类中均使用了JoinColumn配置了外键,即一和多的两方都会维护外键。
-
-
注解说明
-
@OneToMany- 作用:建立一对多的关系映射
- 属性:
targetEntity:对应多的一方的实体类字节码
mappedBy:指定从表实体类中引用主表对象的名称
cascade:指定要使用的级联操作
fetch:指定采用延迟加载或立即加载
orphanRemoval:是否使用孤儿删除
-
@ManyToOne-
作用:建立多对一的关系映射
-
属性:
targetEntity:对应一的一方的实体类字节码
cascade:指定要使用的级联操作
fetch:指定采用延迟加载或立即加载
optional:关联是否可选。如果设置为false,则必须始终存在非空关系
-
-
@JoinColumn-
作用:用于定义主键字段和外键字段的对应关系
-
属性:
name:指定外键字段的名称
referencedColumnName:指定引用主表的主键字段名称
unique:是否唯一。默认值不唯一。
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
-
-
-
一对多的保存操作
@Test @Transactional @Rollback(false) public void testAdd() { //1.创建一个公司,创建一个员工 Customer customer = new Customer(); customer.setCustName("华为"); LinkMan linkMan = new LinkMan(); linkMan.setLkmName("小李"); //2.添加包含关系建立主表和从表的联系 customer.getLinkMans().add(linkMan); linkMan.setCustomer(customer); customerDao.save(customer); linkManDao.save(linkMan); }-
⭐注意:
在上述代码的第2步中,只使用第一条语句,在建立数据库表时会多出一条update语句,用于从主表的角度去维护外键,而仅使用第二条语句时不会出现此类情况。
这是由于在主表实体类和从表实体类中都使用
JoinColumn配置了外键,为了解决主表对外键的重复维护,可以在主表实体类中放弃外键的维护,实体类代码如下:@Entity @Table(name="cst_customer") public class Customer implements Serializable { @Id @GeneratedValue(strategy=GenerationType.IDENTITY) @Column(name="cust_id") private Long custId; ... //一对多关系映射 @OneToMany(mappedBy = "customer") private Set<LinkMan> linkmans = new HashSet<LinkMan>(0); ...//省略Setter、Getter、toString方法 }取消了
JoinColumn的外键配置,OneToMany注解中使用mappedBy属性,取值为从表实体类中对应外键的属性名,以此建立主从表的联系。
-
-
一对多的删除操作
-
对于删除从表,直接进行删除即可
-
对于删除主表:
- 如果删除字段没有关联的从表字段,直接删除即可。
- 如果有关联的从表字段:
- 默认情况会在删除后将从表中的外键值设置为null,如果数据库设置了外键非空,则会报错;
- 如果配置了主表放弃维护外键,则无法删除。
- 如果需要执行删除操作,可以在主表中设置级联操作。
-
级联操作:删除一个对象同时删除与之关联的对象。
- 使用方法:在主表实体类的
@OneToMany注解中设置cascade属性值 - CascadeType.MERGE 级联更新
- CascadeType.PERSIST 级联保存
- CascadeType.REFRESH 级联刷新
- CascadeType.REMOVE 级联删除
- CascadeType.ALL 包含所有
- 使用方法:在主表实体类的
-
主表实体类代码
@Entity @Table(name="cst_customer") public class Customer implements Serializable { @Id @GeneratedValue(strategy=GenerationType.IDENTITY) @Column(name="cust_id") private Long custId; ... //一对多关系映射 @OneToMany(mappedBy = "customer",cascade = CascadeType.ALL) private Set<LinkMan> linkmans = new HashSet<LinkMan>(0); ...//省略Setter、Getter、toString方法 }
-
¶3. 多对多
-
案例:用户与角色
-
编写实体类
-
用户表实体类
@Entity @Table(name = "sys_user") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name="user_id") private Long userId; @Column(name="user_name") private String userName; @Column(name="age") private Integer age; // 配置用户到角色的多对多关系 @ManyToMany(targetEntity = Role.class,cascade = CascadeType.ALL) @JoinTable(name = "sys_user_role", joinColumns = {@JoinColumn(name = "sys_user_id",referencedColumnName = "user_id")}, inverseJoinColumns = {@JoinColumn(name = "sys_role_id",referencedColumnName = "role_id")} ) private Set<Role> roles = new HashSet<>(); ... } -
角色表实体类
@Entity @Table(name = "sys_role") public class Role { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "role_id") private Long roleId; @Column(name = "role_name") private String roleName; //配置多对多 @ManyToMany(mappedBy = "roles") private Set<User> users = new HashSet<>(); ... }
-
-
注解说明
-
@ManyToMany-
作用:用于映射多对多关系
-
属性:
cascade:配置级联操作。
fetch:指定采用延迟加载或立即加载。
targetEntity:配置目标的实体类。
-
-
@JoinTable-
作用:针对中间表的配置
-
属性:
name:配置中间表的名称
joinColumns:当前对象在中间表的外键
inverseJoinColumn:对方对象在中间表的外键
-
-
-
保存操作
@Test @Transactional @Rollback(false) public void testAdd() { User user = new User(); user.setUserName("小李"); Role role = new Role(); role.setRoleName("java程序员"); //2.配置用户到角色关系,可以对中间表中的数据进行维护 1-1 user.getRoles().add(role); //2.配置角色到用户的关系,可以对中间表的数据进行维护 1-1 role.getUsers().add(user); userDao.save(user); roleDao.save(role); }⭐️**注意:**在多对多(保存)中,如果双向都设置关系,意味着双方都维护中间表,都会往中间表插入数据,中间表的2个字段又作为联合主键,所以进行两次中间表的插入操作会导致中间表主键重复而报错,解决办法是在任意一方放弃对中间表的维护权即可。所以在角色表实体类中使用
@ManyToMany(mappedBy="roles")配置即可。
¶4. 对象导航查询
-
查询一个对象的同时,通过此对象查询他的关联对象。
- 查询方法:直接调用相应的get方法即可。
-
查询公司时,获得其下的所有员工
@Test //由于是在java代码中测试,为了解决no session问题,将操作配置到同一个事务中 @Transactional public void testFind() { Customer customer = customerDao.findOne(5l); Set<LinkMan> linkMans = customer.getLinkMans();//对象导航查询 for(LinkMan linkMan : linkMans) { System.out.println(linkMan); } } -
查询员工时,获得其所属公司
@Test @Transactional // 解决在java代码中的no session问题 public void testQuery3() { LinkMan linkMan = linkManDao.findOne(2l); //对象导航查询所属的公司 Customer customer = linkMan.getCustomer(); System.out.println(customer); } -
注意
-
一到多查询时:当查询公司时,其对应的员工数据较多,如果直接查出来浪费服务器资源,默认采用的是延迟加载方式。
-
多到一查询时:当查询员工时,一个对象不会消耗太多内存,默认采用的是立即加载方式。
-
如果需要修改加载方式,在相应的实体类中的直接中加入fetch属性即可。
/** * 在联系人对象的@ManyToOne注解中添加fetch属性 * FetchType.EAGER :立即加载 * FetchType.LAZY :延迟加载 */ @ManyToOne(targetEntity=Customer.class,fetch=FetchType.EAGER) @JoinColumn(name="cst_lkm_id",referencedColumnName="cust_id") private Customer customer;
-
